
Du möchtest wissen, welche Marketingmaßnahme zu einer Conversion geführt hat und wie groß der Anteil am Erfolg war? Mithilfe von Attributionsmodellen kannst du diesen Sachverhalt einfach darstellen. Gastautor Kawa Mohammad, Data Analytics Consultant bei e-dynamics, gibt dir dabei eine Einführung in die unterschiedlichen Modelle und zeigt dir Vor- und Nachteile auf.
Angenommen wir haben das Champions League Finalspiel diesen Sommer verfolgt, welches 3:2 ausging. Wir sind Teil der TV-Expertenrunde, die das Spiel im Anschluss haarklein analysiert. Die Siegermannschaft steht dabei offensichtlich im Fokus. Es geht vor allem um die vier Spieler, die an den drei entscheidenden Toren beteiligt waren und die Frage: Welchen Anteil hatten die einzelnen Spieler an den Toren?
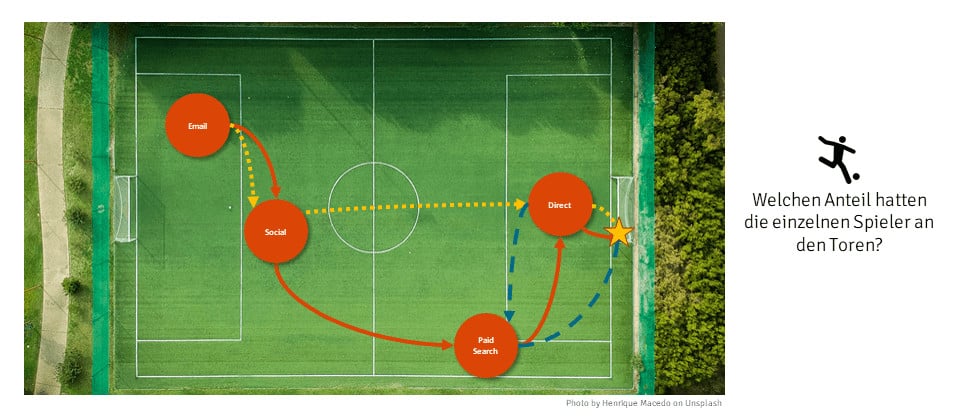
Übertragen wir das obige Beispiel nun auf das Marketing der heutigen Zeit, so stellen die verschiedenen Spieler die unterschiedlichen Kanäle, die für Kampagnen und Werbung genutzt werden, dar. Das Schießen eines Tores bzw. der Sieg ist das Ziel, eine Conversion zu generieren. Die Passabfolge im Fußballspiel kann hierbei durch eine äquivalente Customer Journey ersetzt werden. Die Experten sind die Analysten, die nun bewerten, welchen Anteil die verschiedenen Kanäle an der Conversion haben. Diese Zuweisung der Conversion nennt man Attribution. Wir stellen Euch heute einige Standardmodelle, die sich im Laufe der Zeit in der Attribution etabliert haben sowie die Data Driven Attribution anhand unseres Fußball-Beispiels vor.
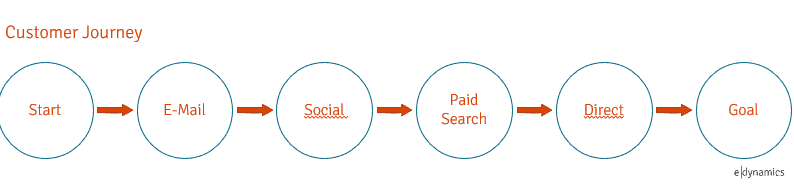
Die Standardmodelle der Attribution
Um in die Standardmodelle einzuführen, werden wir nun beispielhaft jedem Spieler zuordnen, welchen konkreten Anteil er an dem geschossenen Tor erhalten würde.
Single-Touch Attributions Modelle
Last-Touch
Die Credits gehen an den Channel der Session, in dem die Conversion stattgefunden hat, d.h. an den letzten „Channelkontakt“ mit der eigentlichen Conversion. Im obigen Beispiel ist das der Direct-Channel.
First-Touch
Die Conversion wird dem ersten Channel der Customer Journey gutgeschrieben, da durch ihn das Interesse und die Aufmerksamkeit des Users angeregt wurde. Im obigen Beispiel ist das die E-Mail-Kampagne.
Last Non-Direct-Click
Die Conversion wird dem zuletzt bekannten (Non-Direct) Channel zugeordnet. In diesem Fall bleibt die Information, die zu einem Direct-Besuch geführt hat, erhalten und potenziell hoher Direct-Traffic am Ende der Customer Journey wird nicht überschätzt.

Multi-Touch Attribution Model
Fußball ist ein Mannschaftssport. In den seltensten Fällen kann der Sieg auf einen einzelnen Spieler zurückgeführt werden. Genauso verhält es sich mit dem Zusammenspiel der verschiedenen Kanäle. Die Single-Touch Modelle geben oftmals die verschiedenen Einflüsse und das Zusammenspiel der einzelnen Kanäle nicht exakt wieder. Beim Multi-Touch Ansatz wird nun versucht, jeden Kontakt mit dem Produkt, auf dem Weg zur Conversion, in einem gewissen Maße zu berücksichtigen, d.h. die Conversion wird nicht zu 100% einem einzelnen Channel zugeordnet, sondern anteilig auf die Channels verteilt. Die verschiedenen Kanäle werden je nach Modell unterschiedlich gewichtet. Nachfolgend findet ihr zwei Beispiele einer Multi-Touch Attribution.
Linear-Touch
Der lineare Ansatz sieht vor, dass alle Kontakte gleich stark gewichtet werden und denselben Beitrag zur Conversion leisten. Daher wird jedem Channel pro Anzahl an Sessions in der Customer Journey der gleiche Anteil zugeteilt. Zwar ist dieser Ansatz schon erheblich objektiver als das Single-Touch Modell, jedoch nicht besonders aussagekräftig, falls ein Kanal besonders heraussticht.
U-Model
Hier wird nun versucht, die Vorteile von First-, Last- und Linear-Touch zu kombinieren. Alle Kanäle, mit denen der Kunde in Kontakt getreten ist, haben ihn schlussendlich zur Kaufentscheidung bewegt und werden demnach berücksichtigt. Hierbei haben der erste und der letzte Kontakt den größten Anteil an der Conversion, da der First-Touch das Interesse geweckt und der Last-Touch den Kunden zum Kauf bewegt hat.
ÄhnlicheArtikel




Fazit zu den Standardmodellen
Anhand unseres pragmatischen Beispiels werden die Vor- und Nachteile der verschiedenen Modelle ersichtlich: Je nachdem, welches Modell von uns ausgewählt wird, wird ein bestimmter Kanal begünstigt bzw. benachteiligt, indem die Gewichtung der Kanäle umverteilt wird. Wichtig ist hierbei, dass insgesamt bei keinem Modell Conversions verloren gehen – auch wenn es bei der Auswertung von einzelnen Kanälen bei einem Modellwechsel große Unterschiede geben kann. Alle Modelle sind in ihrem Sinne begründet und korrekt, allerdings können in der Unternehmenspraxis starke Interessenskonflikte resultieren, da sich jede Partei die bestmögliche Bewertung für ihren Channel wünscht.

Eine fundierte und objektive Analyse über die Performance der Kanäle, deren Effektivität und Beitrag zur Conversion kann demnach nur bedingt erfolgen. Sollen komplexe Zusammenhänge einer Website dargestellt werden, kann die Anwendung simpler Standardmodelle zu groben Fehlannahmen führen. Daher schlagen wir euch nun einen Weg vor, der weg von den Standardmodellen hin zur datengetriebenen Attribution geht. Seid Ihr bereit für einen Data Deep Dive?
Data Driven Attribution
Um euch die datengetriebene Attribution verständlich vorstellen zu können, wenden wir die Methoden wieder auf alle drei geschossenen Tore unserer Siegermannschaft an.
Shapley Value
Eine Herangehensweise, bei der man versucht, die Tore auf die einzelnen Spieler zu verteilen ist der sogenannte „Shapley Value“. Um den konkreten Anteil an den Toren eines Spielers ermitteln zu können, wird berechnet, inwiefern sich die Tore verändern würden, wenn ein Spieler zu einem Team von anderen Spielern hinzugefügt werden würde. Zu diesem Zweck wird zunächst die Anzahl der Möglichkeiten ermittelt, vier Spieler auf vier Plätze zu verteilen.
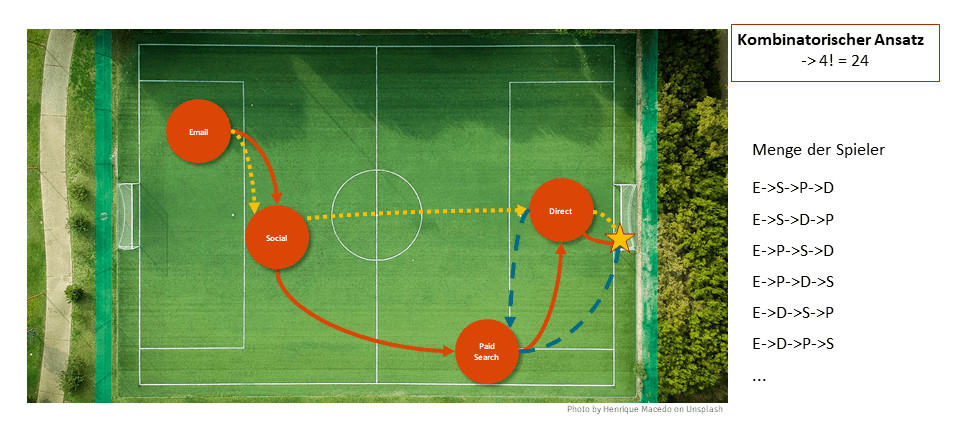
Daraus ergeben sich in unserem Beispiel genau 24 Fälle. Möchten wir den Wert von E-Mail ausrechnen, betrachten wir eine Menge an Spielern ohne E-Mail und die Anzahl der Tore x, die diese Gruppe schießt. Anschließend fügen wir den Spieler E-Mail zu dieser Gruppe hinzu und berechnen wie viele Tore y mit Email geschossen werden. Die Differenz z = y-x ist der Mehrwert des Spielers E-Mail in dieser Gruppenkonstellation.
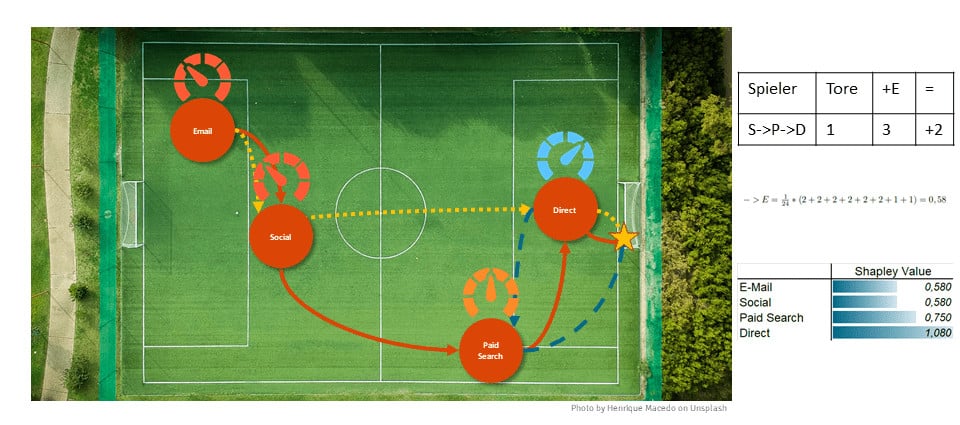
Wir verzichten in unserem Beispiel auf die Reihenfolge der Spieler, d.h. die Gruppe [S, P, D] schießt genau wie die Gruppe [S, D, P] ein Tor. Fügt man nun beiden Gruppen den Spieler E-Mail hinzu, so schießt die erweiterte Gruppe drei Tore und wir erhalten in beiden Fällen einen Mehrwert von zwei Toren. Geht man nun alle Fälle durch, addiert die jeweiligen Mehrwerte auf und dividiert diesen Wert mit der Gesamtanzahl an Fällen, ergibt sich der Anteil des Spielers E-Mail an den drei geschossenen Toren. Somit kommt E-Mail auf insgesamt 0,58 geschossene Tore.
Markov-Ketten
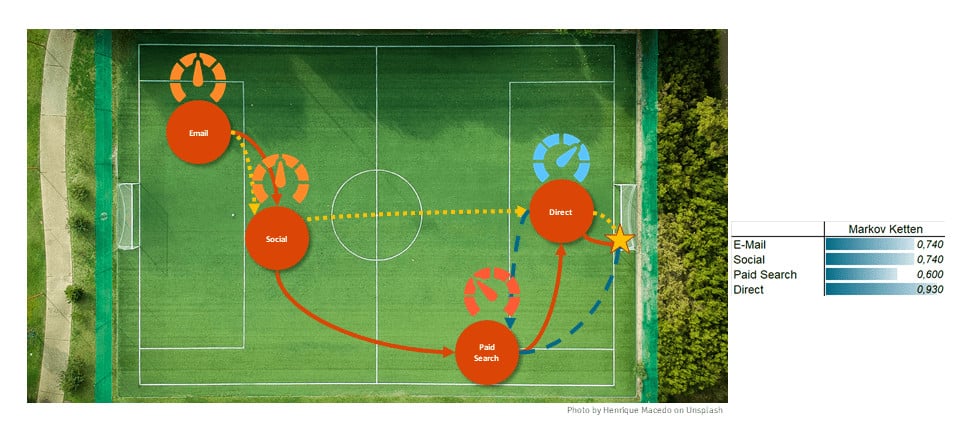
Die Markov-Ketten betrachten den Fall, dass ein Spieler aus der gesamten Gruppe entfernt wird. Dies wird auch „Removal Effect“ genannt. In anderen Worten: Man berechnet den Verlust an Toren, der entsteht, wenn ein Spieler ausfällt. Im ersten Schritt betrachten wir die sogenannten „Channeleinstiege“, sprich das Einleiten der Tore. Anschließend berechnen wir die Wahrscheinlichkeiten aller Pässe und Tore. Der Einfachheit halber betrachten wir nur die tatsächlichen Pässe und Tore. Um den Anteil des Spielers E-Mail an den drei Toren zu berechnen, werden wir ihn aus dem Spiel nehmen. Die Grafik kann somit wie folgt vereinfacht werden.

Die Anzahl der Tore fällt von eins (drei Tore wurden geschossen) auf 0,33 (die beiden Spieler Direct und Paid Search schießen nur ein Tor). Wir verzeichnen somit einen Verlust von 0,67, sprich es werden zwei Tore weniger geschossen. Der Anteil von E-Mail an den drei Toren kann nun wie folgt berechnet werden: Anzahl aller geschossener Tore multipliziert mit dem Verlust von E-Mail dividiert durch die Summe der Verluste der einzelnen Spieler, ergibt: 0,74 Tore.
Fazit zur Data Driven Attribution
Wir haben gesehen, dass bei der datengetriebenen Attribution viel Vorarbeit geleistet werden muss. Ein weiterer Nachteil ist, dass die oben eingeführten Verfahren sehr schnell komplex werden können. So würden wir z.B. beim Shapley Value auf rund 720 zu betrachtende Fälle kommen, wenn wir sieben Spieler berücksichtigen. Das hat zur Folge, dass solche Verfahren sehr zeit- und rechenintensiv sind. Neben der benötigten Expertise, um solche Verfahren fehlerfrei und korrekt anwenden zu können, wird somit auch viel Kapazität einverlangt. Sollen zusätzlich Offline Channel berücksichtigt werden, sind diese beiden Verfahren praktisch nicht mehr anwendbar.
Daher empfehlen wir zunächst die Standardmodelle anzuwenden. Hierdurch lernt man seine Kunden kennen, kann die Customer Journey nachvollziehen und hat bereits einen groben Überblick, wie die einzelnen Kanäle „performen“ könnten. Reicht dies nicht aus und kommt man mit den Standardmodellen an sein Limit, empfehlen wir zur DDA überzugehen. Hierdurch erhält man eine objektive Betrachtungsweise und vermeidet Interessenskonflikte innerhalb des Unternehmens. Beide oben vorgestellten Modelle sind relativ leicht implementierbar und können sehr gut interpretiert werden. Dabei kann sogar die Reihenfolge der besuchten Kanäle bei der Customer Journey berücksichtigt werden. Ein weiterer Vorteil ist, dass die tatsächliche Menge an Conversions neu auf die Kanäle verteilt wird. Die Markov-Ketten bieten zusätzlich die Möglichkeit einer Visualisierung der Channel-Wechselwirkungen anhand übersichtlicher Graphen. Entscheidet man sich für die Lineare Regression, so können neben dem Channel-Traffic auch alle anderen Daten in das Modell einfließen, wodurch Einflüsse einzelner Merkmale gut herausgestellt werden können. Die Resultate können anhand der Daten statistisch belegt werden, die im optimalen Fall nicht nur eine Beschreibung des Beobachtungszeitraums, sondern auch Empfehlungen und Vorhersagen liefern.
Dir hat dieser Artikel gefallen? Erfahre von den ABOUT YOU Guys wie der E-Commerce Riese sein Performance Marketing steuert.

















{kind=link}